pacman::p_load(
haven, # lectura de datos formato externo
car, # función scatterplot y otras de manejo de datos
corrplot, # correlaciones
dplyr, # varios gestión de datos
stargazer, # tablas
lme4) # multilevelPráctica 2. Datos y estimaciones en dos niveles
Correspondiente a la sesión del jueves, 20 de marzo de 2025
Presentación
Objetivo de la práctica
Repasar contenidos relacionados con la estimación de regresión lineal
Preparar y manipular datos a distintos niveles y comprender la diferencia de estimaciones a distintos niveles.
Instalación de librerías
Lectura de datos High School & Beyond (HSB
High School & Beyond (HSB) es una muestra representativa nacional de educación secundaria publica y católica de USA implementada por el National Center for Education Statistics (NCES). Esta base de datos se utiliza en varios textos dedicados a multinivel.
Más información en https://nces.ed.gov/surveys/hsb/
En formato stata desde sitio web
mlm = read_dta("http://www.stata-press.com/data/mlmus3/hsb.dta")mlm es el nombre que le daremos al objeto base de datos “High School and Beyond” en nuestra práctica.
Variables relevantes para ejercicios:
- Nivel 1:
- minority, an indicator for student ethnicity (1 = minority, 0 = other)
- female, an indicator for student gender (1 = female, 0 = male)
- ses, a standardized scale constructed from variables measuring parental education, occupation, and income
- mathach, a measure of mathematics achievement
- Nivel 2
- size (school enrollment)
- sector (1 = Catholic, 0 = public)
- pracad (proportion of students in the academic track)
- disclim (a scale measuring disciplinary climate)
- himnty (1 = more than 40% minority enrollment, 0 = less than 40%)
- mnses (mean of the SES values for the students in this school who are included in the level-1 file)
- Cluster variable: schoolid
Exploración y descripción
dim(mlm) # dimensiones de base de datos[1] 7185 26names(mlm) # Muestra los nombres de las variables en la base [1] "minority" "female" "ses" "mathach" "size" "sector"
[7] "pracad" "disclim" "himinty" "schoolid" "mean" "sd"
[13] "sdalt" "junk" "sdalt2" "num" "se" "sealt"
[19] "sealt2" "t2" "t2alt" "pickone" "mmses" "mnses"
[25] "xb" "resid" Seleccionar variables de interes
mlm=mlm %>% select(minority,
female,
ses,
mathach,
size,
sector,
pracad,
disclim,
himinty,
mnses,
schoolid) %>%
as.data.frame()
dim(mlm)[1] 7185 11head(mlm) # Muestra los primeros 10 casos para cada variable minority female ses mathach size sector pracad disclim himinty mnses
1 0 1 -1.528 5.876 842 0 0.35 1.597 0 -0.434383
2 0 1 -0.588 19.708 842 0 0.35 1.597 0 -0.434383
3 0 0 -0.528 20.349 842 0 0.35 1.597 0 -0.434383
4 0 0 -0.668 8.781 842 0 0.35 1.597 0 -0.434383
5 0 0 -0.158 17.898 842 0 0.35 1.597 0 -0.434383
6 0 0 0.022 4.583 842 0 0.35 1.597 0 -0.434383
schoolid
1 1224
2 1224
3 1224
4 1224
5 1224
6 1224summary(mlm) # Descriptivos generales (evaluación de datos perdidos) minority female ses mathach
Min. :0.0000 Min. :0.0000 Min. :-3.758000 Min. :-2.832
1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:-0.538000 1st Qu.: 7.275
Median :0.0000 Median :1.0000 Median : 0.002000 Median :13.131
Mean :0.2747 Mean :0.5282 Mean : 0.000143 Mean :12.748
3rd Qu.:1.0000 3rd Qu.:1.0000 3rd Qu.: 0.602000 3rd Qu.:18.317
Max. :1.0000 Max. :1.0000 Max. : 2.692000 Max. :24.993
size sector pracad disclim
Min. : 100 Min. :0.0000 Min. :0.0000 Min. :-2.4160
1st Qu.: 565 1st Qu.:0.0000 1st Qu.:0.3200 1st Qu.:-0.8170
Median :1016 Median :0.0000 Median :0.5300 Median :-0.2310
Mean :1057 Mean :0.4931 Mean :0.5345 Mean :-0.1319
3rd Qu.:1436 3rd Qu.:1.0000 3rd Qu.:0.7000 3rd Qu.: 0.4600
Max. :2713 Max. :1.0000 Max. :1.0000 Max. : 2.7560
himinty mnses schoolid
Min. :0.00 Min. :-1.1939460 Min. :1224
1st Qu.:0.00 1st Qu.:-0.3230000 1st Qu.:3020
Median :0.00 Median : 0.0320000 Median :5192
Mean :0.28 Mean : 0.0001434 Mean :5278
3rd Qu.:1.00 3rd Qu.: 0.3269123 3rd Qu.:7342
Max. :1.00 Max. : 0.8249825 Max. :9586 Tabla descriptiva con stargazer:
stargazer posee tres opciones básicas de output: text, html o latex (defecto). Si se quiere ver el contenido directamente en formato txt en la consola de R con fines exploratorios, usar text. Si se quiere reportar luego via knitr a html cambiar a html, y si se quiere exportar a pdf cambiar a Latex. Recomendación general: dejar inicialmente como text hasta el reporte final de resultados, facilita la visualización en la consola y no requiere tener que compilar para ver el resultado (en el caso de trabajar con Rmarkdown)
stargazer(mlm, title = "Descriptivos generales", type='text')
Descriptivos generales
=================================================
Statistic N Mean St. Dev. Min Max
-------------------------------------------------
minority 7,185 0.275 0.446 0 1
female 7,185 0.528 0.499 0 1
ses 7,185 0.0001 0.779 -3.758 2.692
mathach 7,185 12.748 6.878 -2.832 24.993
size 7,185 1,056.862 604.172 100 2,713
sector 7,185 0.493 0.500 0 1
pracad 7,185 0.534 0.251 0.000 1.000
disclim 7,185 -0.132 0.944 -2.416 2.756
himinty 7,185 0.280 0.449 0 1
mnses 7,185 0.0001 0.414 -1.194 0.825
schoolid 7,185 5,277.898 2,499.578 1,224 9,586
-------------------------------------------------- y con html…
stargazer(mlm, title = "Descriptivos generales", type='html')| Statistic | N | Mean | St. Dev. | Min | Max |
| minority | 7,185 | 0.275 | 0.446 | 0 | 1 |
| female | 7,185 | 0.528 | 0.499 | 0 | 1 |
| ses | 7,185 | 0.0001 | 0.779 | -3.758 | 2.692 |
| mathach | 7,185 | 12.748 | 6.878 | -2.832 | 24.993 |
| size | 7,185 | 1,056.862 | 604.172 | 100 | 2,713 |
| sector | 7,185 | 0.493 | 0.500 | 0 | 1 |
| pracad | 7,185 | 0.534 | 0.251 | 0.000 | 1.000 |
| disclim | 7,185 | -0.132 | 0.944 | -2.416 | 2.756 |
| himinty | 7,185 | 0.280 | 0.449 | 0 | 1 |
| mnses | 7,185 | 0.0001 | 0.414 | -1.194 | 0.825 |
| schoolid | 7,185 | 5,277.898 | 2,499.578 | 1,224 | 9,586 |
Nota
Para que se pueda obtener la tabla en html se debe agregar en las opciones del chunk en R results='asis'
Datos perdidos: crear una nueva base sin missing values (Listwise Deletion) (solo recomendado para objetos que contienen las variables a incluir en el modelo)
mlm2=na.omit(mlm) #Sacar missing data
names(mlm2)
summary(mlm2)Exploración visual de datos
hist(mlm$mathach, xlim = c(0,30))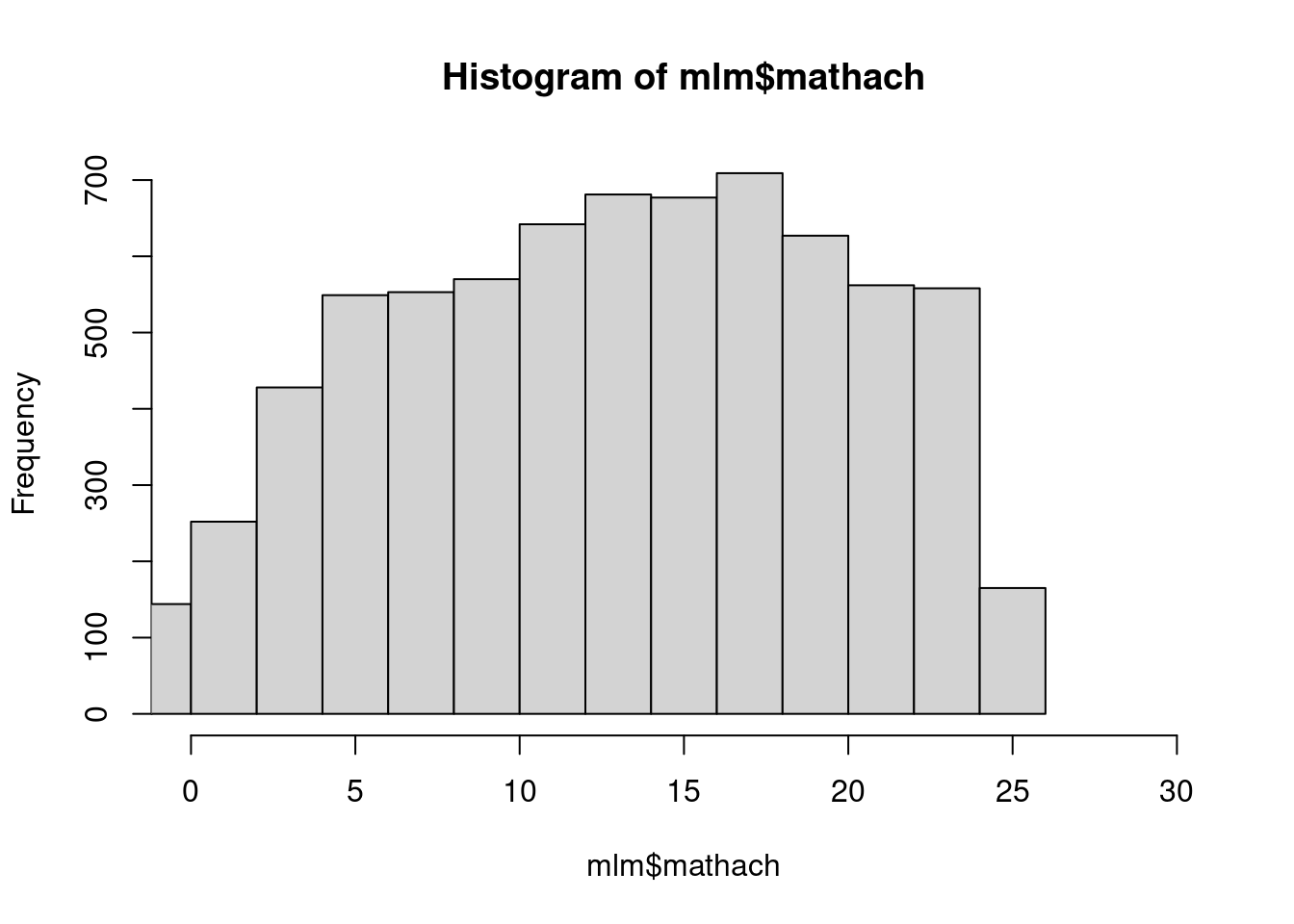
Matriz de correlaciones de un subset de variables
cormat=mlm %>% select(mathach,ses,sector,size) %>% cor()
round(cormat, digits=2) mathach ses sector size
mathach 1.00 0.36 0.20 -0.05
ses 0.36 1.00 0.19 -0.07
sector 0.20 0.19 1.00 -0.42
size -0.05 -0.07 -0.42 1.00corrplot.mixed(cormat)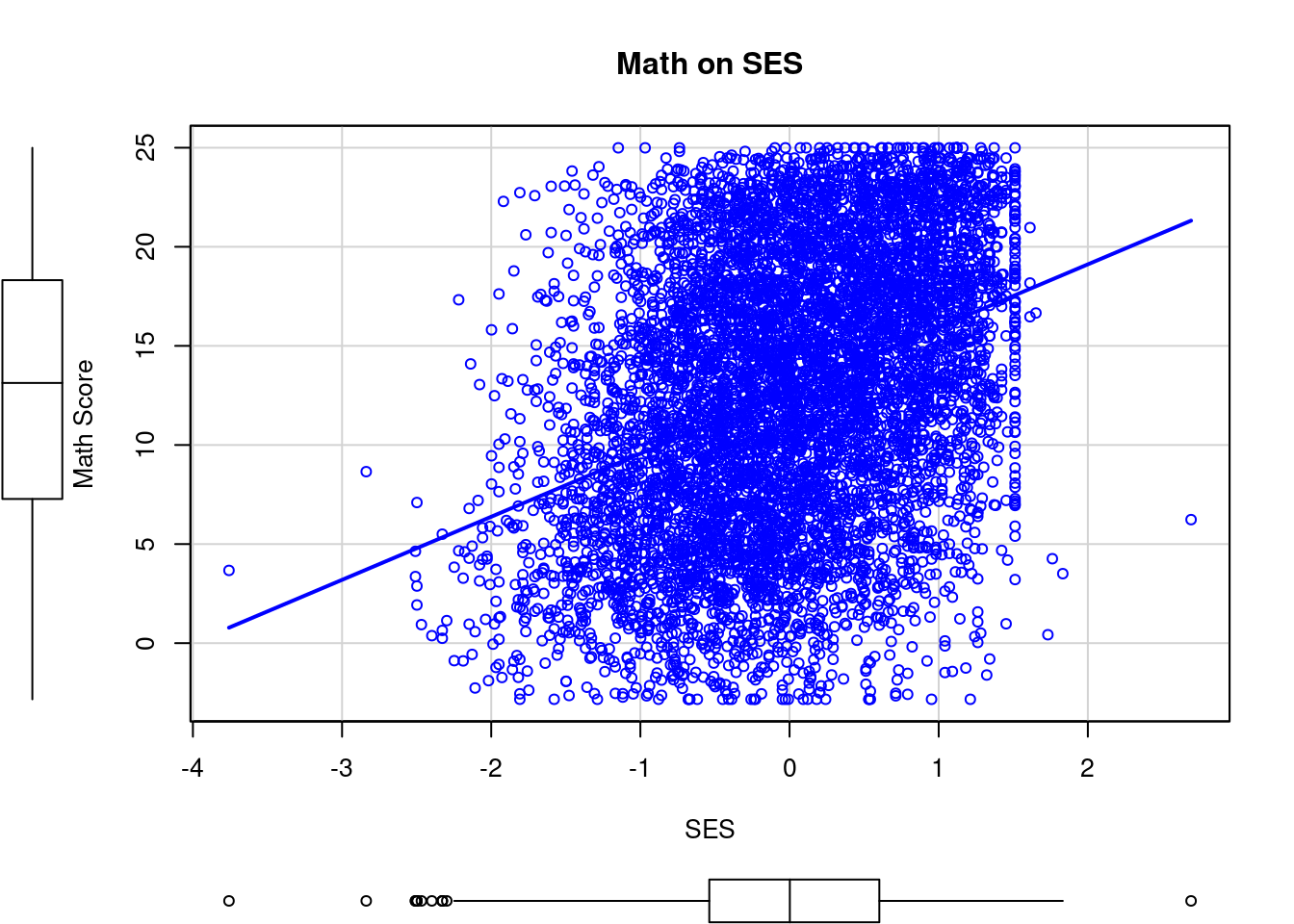
Repaso de regresión lineal
Medias condicionales
Antes de avanzar desde la correlación al método de regresión es importante conocer el concepto de media condicional.
Imaginemos un juego de tacataca con dos variables: cantidad de juegos previos y puntos obtenidos en un partido. En estas variables, el promedio de puntos es 4. Es decir, si conocemos a algún individuo que pertence al grupo de “datos”, sabemos que su puntaje se encuentra probablemente cercano a 4. ¿Podemos mejorar nuestra estimación utilizando el puntaje de X? Si el sujeto nos dice que ha jugado antes 6 veces, probablemente vamos a estimar un puntaje superior de puntos, tal vez más cercano a 6.
Lo que estamos haciendo es utilizar la información que conocemos de X para dar una estimación de Y, que sea más precisa que el promedio bruto.
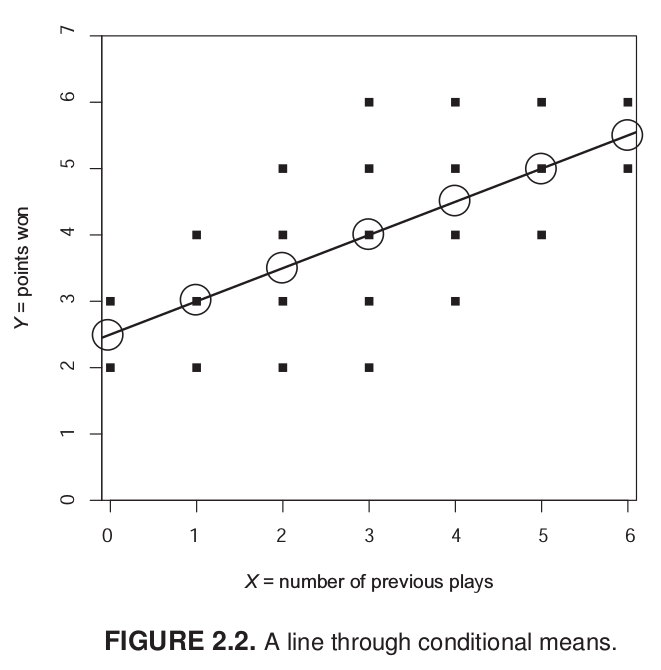
Mirando el gráfico de nube de puntos, sabemos que tres personas han jugado antes una vez, pero una de ellas tuvo 2 puntos, otra 3 y otra 4. Con estos datos podemos calcular la media de Y para X=1, que sería igual a 3. En otras palabras, la media condicional de Y cuando X=1 es 3. Con esto, uno podría calcular la media condicional para cada punto de X y hacer una estimación más precisa de Y. Sin embargo, este proceso todavía no nos permite generalizar más eficientemte la relación entre X e Y.
¿Cuántos puntos (Y) se obtienen según la experiencia previa de juego (X)? Esta pregunta nos conduce al cálculo de una recta que atraviese los puntos y que generalice la relación entre X e Y.
Residuos
En el gráfico anterior vemos que la línea resume la relación entre X e Y, pero claramente es una simplificación que no abarca toda la variabilidad de los datos.
Por ejemplo, para el sujeto cuya experiencia es haber jugado 1 vez y luego gana 3 puntos, esta línea predice exáctamente su puntaje basada en su experiencia. Sin embargo, el sujeto que ha jugado 3 veces y saca 6 puntos se encuentra más lejos de la línea y por lo tanto esta línea o “modelo predictivo” no representa tan bien su puntaje. A esto se refieren los residuos, que es la diferencia entre el valor predicho (o \(\widehat{Y}\)) y el observado \(Y\), siendo los valores predichos de Y los que pasan por la recta a la altura de cada valor de X. Por lo tanto, la mejor recta será aquella que minimice al máximo los residuos.
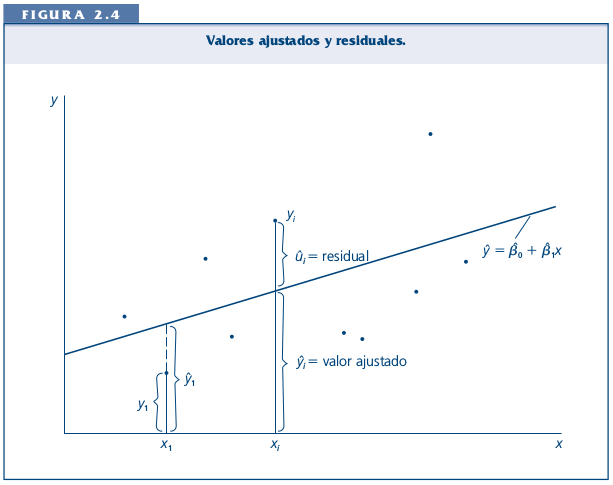
El sentido de la recta que resume de mejor manera la relación entre dos variables es que minimice la suma de todos los residuos. ¿Cómo realizar este procedimiento?
Para realizar la suma de los residuos estos se elevan al cuadrado, lo que se denomina Suma de residuos al cuadrado o \(SS_{residual}\). Se eleva al cuadrado ya que como hay residuos positivos y negativos, unos cancelarían a otros y la suma seía 0, tal como sucede en la formula de la varianza.
De la infinita cantidad de rectas que se pueden trazar, siempre hay una que tiene un valor menor de \(SS_{residual}\). Este procedimiento es el que da nombre al proceso de estimación: mínimos (residuos) cuadrados ordinarios, o OLS (Ordinary Least Squares).
¿Cómo funciona esto con nuestro ejemplo?
summary(mlm$mathach) Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.832 7.275 13.131 12.748 18.317 24.993 scatterplot(mlm$mathach ~ mlm$ses, data=mlm, xlab="SES", ylab="Math Score", main="Math on SES", smooth=FALSE)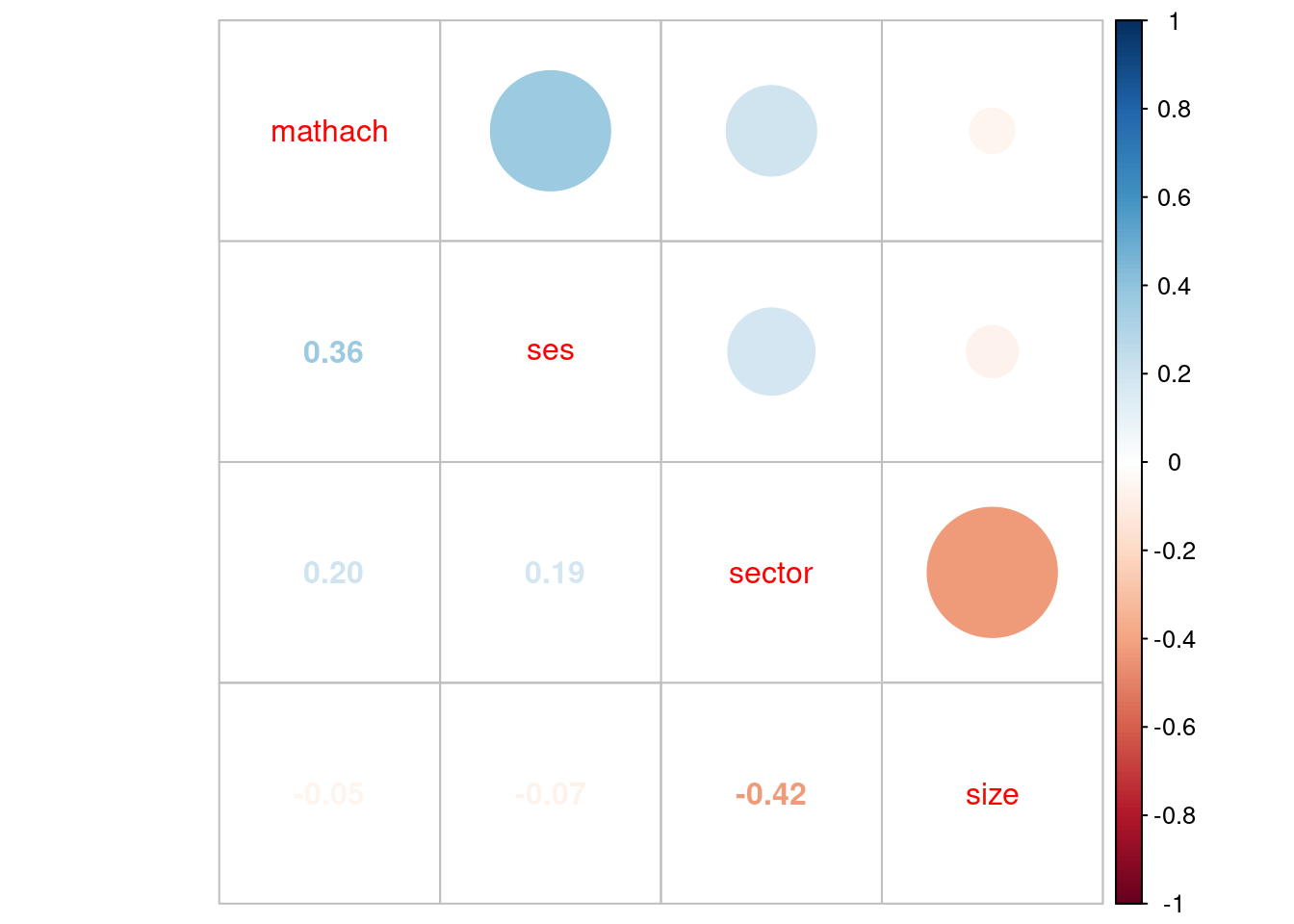
Con el gráfico anterior podemos notar que, si bien existe una asociación positiva entre el nivel socioeconómico y el logro en la prueba de matemáticas, existe una gran cantidad de ‘puntos’ que quedan fuera de la recta de regresión (residuos).
Modelo de regresión y cálculo de parámetros
El modelo de regresión se representa con una ecuación de la recta, o recta de regresión. Esta recta representa los valores predichos para Y según los distintos valores de X:
\[ \widehat{Y} = b_{0} + b_{1}X \tag{1}\]
Donde
- \(\widehat{Y}\) es el valor estimado/predicho de \(Y\)
- \(b_{0}\) es el intercepto de la recta (el valor de Y cuando X es 0)
- \(b_{1}\) es el coeficiente de regresión, que nos dice cuánto aumenta Y por cada punto que aumenta X (pendiente)
Cálculo de los parámetros del modelo de regresión
\(b_{1}\), o comunmente llamado “beta de regresión” se obtiene de la siguiente manera:
\[ b_{1} = \frac{\text{Cov}(X,Y)}{\text{Var}(X)} \tag{2}\]
En términos más suntantivos se puede entender como qué parte de la covariación que hay entre X e Y se relaciona con (la varianza de) X. Especificando la fórmula:
\[ b_{1} = \frac{\frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{n-1}}{\frac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{n-1}} \tag{3}\]
Y simplificando
\[ b_{1} = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n}(x_i - \bar{x})^2} \tag{4}\]
Como sabemos, la base para todos estos cálculos es el valor de cada variable menos su promedio. Vamos a crear un vector en nuestra base de datos difx=\(x-\bar{x}\) y dify=\(y-\bar{y}\)
mlm$difx=mlm$ses-mean(mlm$ses)
mlm$dify=mlm$mathach-mean(mlm$mathach)Y ahora con esto podemos obtener la diferencia de productos cruzados dif_cru=\((x-\bar{x})*(y-\bar{y})\), así como la diferencia de X de su promedio al cuadrado SSx=\((x-\bar{x})^2\)
mlm$difcru=mlm$difx*mlm$dify
mlm$difx2=mlm$difx^2Y con esto podemos obtener la suma de productos cruzados y la suma de cuadrados de X
sum(mlm$difcru)[1] 13892.89sum(mlm$difx2)[1] 4363.522Reemplazando en la fórmula
\[b_{1}=\frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})} {\sum_{i=1}^{n}(x_i - \bar{x})(x_i - \bar{x})}=\frac{13892.89}{4363.522}=3.18\]
Y con esto podemos obtener el valor de \(b_{0}\)
\[b_{0}=\bar{Y}-b_{1}\bar{X}\] \[b_{0}=12.748-(0.0001 * 3.18)=12.747\]
Completando la ecuación:
\[\bar{Y}=12.747+3.18X\]
Esto nos permite estimar el valor de \(Y\) (o su media condicional) basado en el puntaje \(X\). Por ejemplo, cuál es el valor estimado de \(Y\) dado \(X=5\)?
Estimación del modelo de regresión simple en R
La función para estimar regresión en R es lm (linear model). Su forma general es:
objeto=lm(dependiente ~ independiente, data=datos)Donde
- objeto: el nombre (cualquiera) que le damos al objeto donde se guardan los resultados de la estimación
- dependiente / independiente: los nombres de las variables en los datos
- data = el nombre del objeto de nuestros datos en R
Ejemplo con nuestros datos:
reg <- lm(mathach~ses, data=mlm)Con esta operación ya estimamos nuestra primera regresión simple. Para ver la estimación de los parámetros principales (intercepto y pendiente) simplemente ejecutamos el nombre del objeto:
reg
Call:
lm(formula = mathach ~ ses, data = mlm)
Coefficients:
(Intercept) ses
12.747 3.184 Y obtenemos los valores que calculamos previamente.
Podemos tener un output en un formato más apropiado utilizando la librería stargazer
stargazer(reg, type = "text")
===============================================
Dependent variable:
---------------------------
mathach
-----------------------------------------------
ses 3.184***
(0.097)
Constant 12.747***
(0.076)
-----------------------------------------------
Observations 7,185
R2 0.130
Adjusted R2 0.130
Residual Std. Error 6.416 (df = 7183)
F Statistic 1,074.695*** (df = 1; 7183)
===============================================
Note: *p<0.1; **p<0.05; ***p<0.01Estimación de regresiones
Nivel 1
reg1<- lm(mathach~1, data=mlm)
reg2<- lm(mathach~ses, data=mlm)
reg3<- lm(mathach~ses+female, data=mlm)
reg4<- lm(mathach~ses+female+sector, data=mlm)
reg5<- lm(mathach~ses+female+sector+minority, data=mlm)
summary(reg5)
Call:
lm(formula = mathach ~ ses + female + sector + minority, data = mlm)
Residuals:
Min 1Q Median 3Q Max
-20.2286 -4.5076 0.2104 4.7472 17.8078
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 13.24158 0.13386 98.924 <2e-16 ***
ses 2.36392 0.09946 23.768 <2e-16 ***
female -1.42166 0.14608 -9.732 <2e-16 ***
sector 2.25492 0.14906 15.127 <2e-16 ***
minority -3.11239 0.17029 -18.277 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.166 on 7180 degrees of freedom
Multiple R-squared: 0.1969, Adjusted R-squared: 0.1965
F-statistic: 440.1 on 4 and 7180 DF, p-value: < 2.2e-16stargazer(reg5, title = "Regresión datos individuales", type='text')
Regresión datos individuales
===============================================
Dependent variable:
---------------------------
mathach
-----------------------------------------------
ses 2.364***
(0.099)
female -1.422***
(0.146)
sector 2.255***
(0.149)
minority -3.112***
(0.170)
Constant 13.242***
(0.134)
-----------------------------------------------
Observations 7,185
R2 0.197
Adjusted R2 0.196
Residual Std. Error 6.166 (df = 7180)
F Statistic 440.111*** (df = 4; 7180)
===============================================
Note: *p<0.1; **p<0.05; ***p<0.01Diagnóstico de residuos (con librería car)
influenceIndexPlot(reg5, vars=c("Cook", "Studentized", "hat"), id.n=5)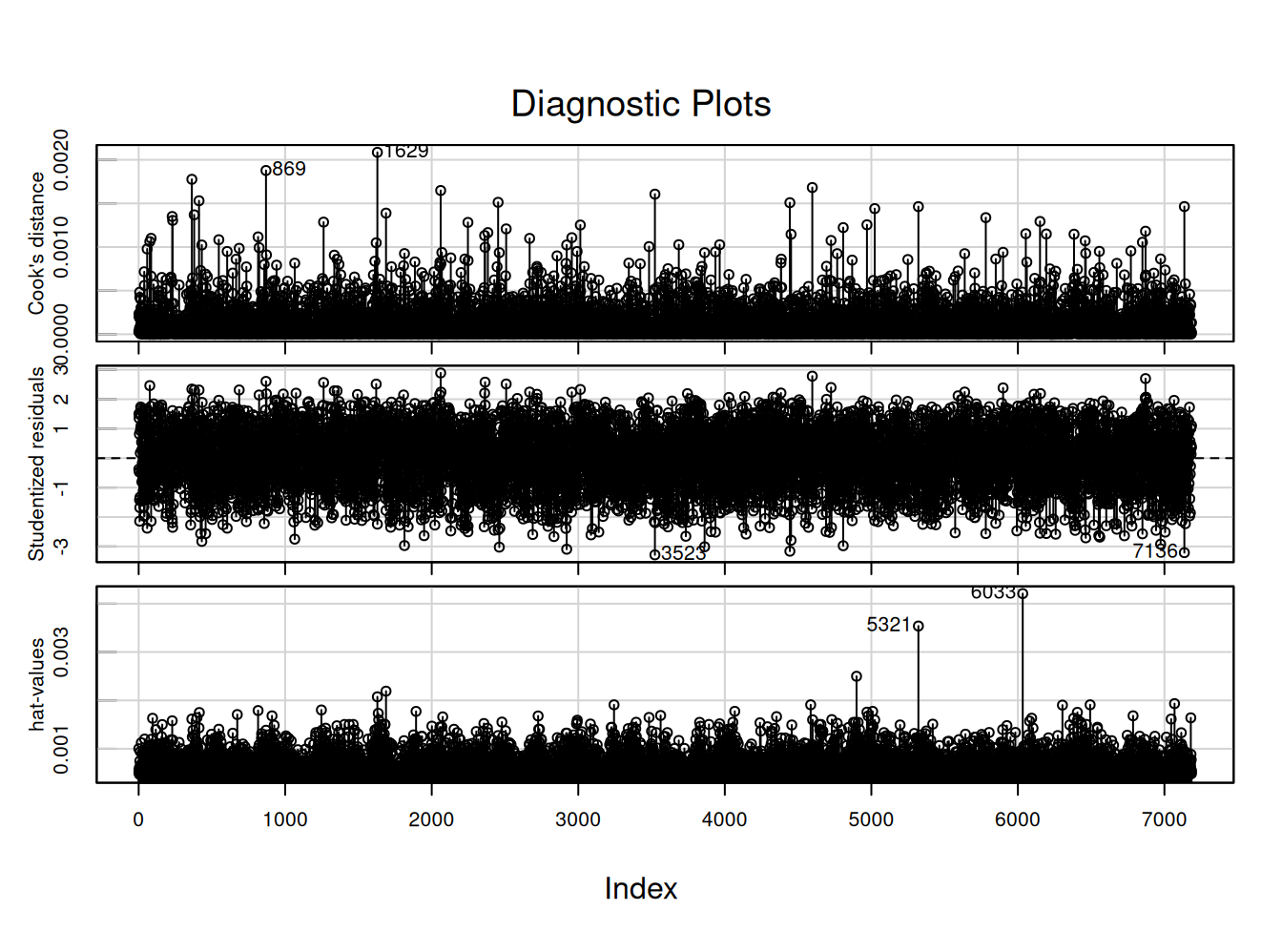
influencePlot(reg5, id.n=3) # el tama~no de los circulos se refiere a la D de Cook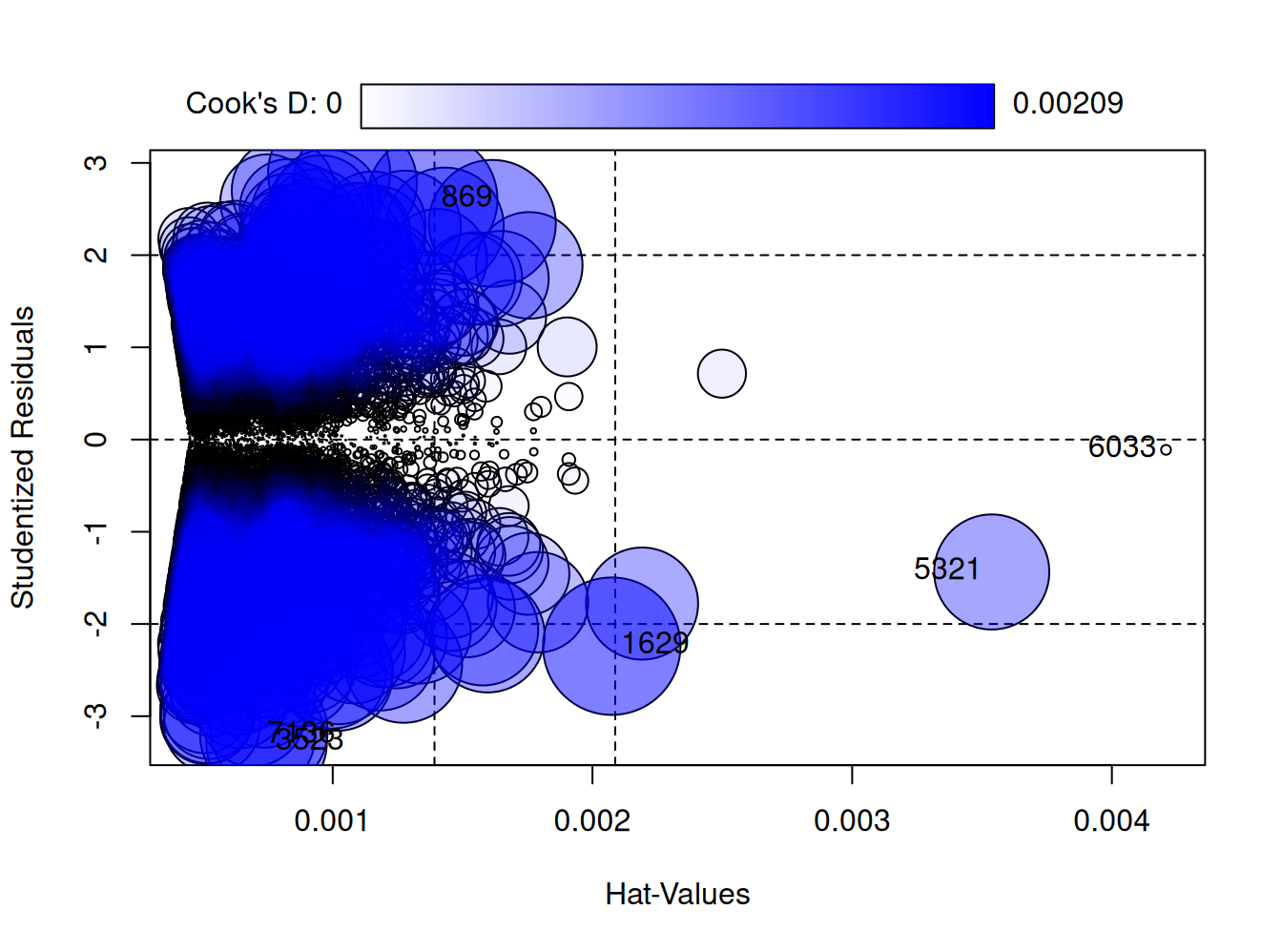
StudRes Hat CookD
869 2.6047540 0.0013831364 0.0018779316
1629 -2.2407411 0.0020743123 0.0020861529
3523 -3.2842968 0.0007451964 0.0016066368
5321 -1.4359364 0.0035373357 0.0014636979
6033 -0.1116449 0.0042083659 0.0000105369
7136 -3.2099858 0.0007110209 0.0014644182Preparando datos agregados
En esta sección vamos a generar una base de datos agregada o colapsada, es decir, una base de datos donde los casos serán escuelas (no individuos). El objetivo de generar esta base es para poder realizar comparaciones con las estimaciones realizadas con la base de datos individuales. Estas estimaciones que realizaremos por separados serán luego integradas en una sola estimación mediante métodos multinivel.
Generación de base agregada
- Usando la funcion
group_by(agrupar por) de la libreríadplyr - Se agrupa por la variable cluster, que identifica a las unidades de nivel 2 (en este caso,
schoolid) - Por defecto se hace con el promedio, pero se pueden hacer otras funciones como contar, porcentajes, mediana, etc.
Para ello:
generamos el objeto
agg_mlmdesde el objetomlmagrupando por la variable cluster
schoolidagregamos (colapsamos) todas
summarise_allpor el promediofuns(mean)
agg_mlm=mlm %>% group_by(schoolid) %>% summarise_all(funs(mean)) %>% as.data.frame()
stargazer(agg_mlm, type = "text")Comparando regresiones
reg5_agg<- lm(mathach~ses+female+sector+minority, data=agg_mlm)
stargazer(reg5,reg5_agg, title = "Comparación de modelos",column.labels=c("Individual","Agregado"), type ='text')
Comparación de modelos
=====================================================================
Dependent variable:
-------------------------------------------------
mathach
Individual Agregado
(1) (2)
---------------------------------------------------------------------
ses 2.364*** 4.204***
(0.099) (0.418)
female -1.422*** -1.997***
(0.146) (0.532)
sector 2.255*** 1.635***
(0.149) (0.302)
minority -3.112*** -2.343***
(0.170) (0.534)
Constant 13.242*** 13.613***
(0.134) (0.347)
---------------------------------------------------------------------
Observations 7,185 160
R2 0.197 0.711
Adjusted R2 0.196 0.703
Residual Std. Error 6.166 (df = 7180) 1.699 (df = 155)
F Statistic 440.111*** (df = 4; 7180) 95.124*** (df = 4; 155)
=====================================================================
Note: *p<0.1; **p<0.05; ***p<0.01¿Qué diferencias existen entre ambas estimaciones? ¿Qué problemas o sesgos podría ocasionar el realizar estimaciones paralelamente en dos niveles?